Messaging is a way of communicating between systems, services or components. Message-driven architectures, especially event-driven architectures, are on the rise thanks to service-based approaches to software architecture such as microservices.
In this post, an overview will be offered of the primitives used in messaging: messages. Furthermore, Data Transfer Objects as a way of implementating messages and use cases are discussed. Finally, it is proposed that Data Transfer Objects can be used to reflect the use cases of an application.
Messages
A message contains data about something that has happened in past, something that is intended to happen in the future or a request for information. Messages describe past or desired future behaviour. Within a message, the data itself is often referred to as its payload, while metadata associated with the message, is often called the envelope of the message. For instance, the message’s addressees (if any), its delivery requirements and place in the system (ID, correlation ID, subject, timestamp) could be added in its envelope.
Messaging patterns are used to decouple sender and receiver or decreasing or distributing the load endured when processing the received message. They can be leveraged for creating resilient, reactive systems.
In general, there are three types of messages: events, commands and queries.
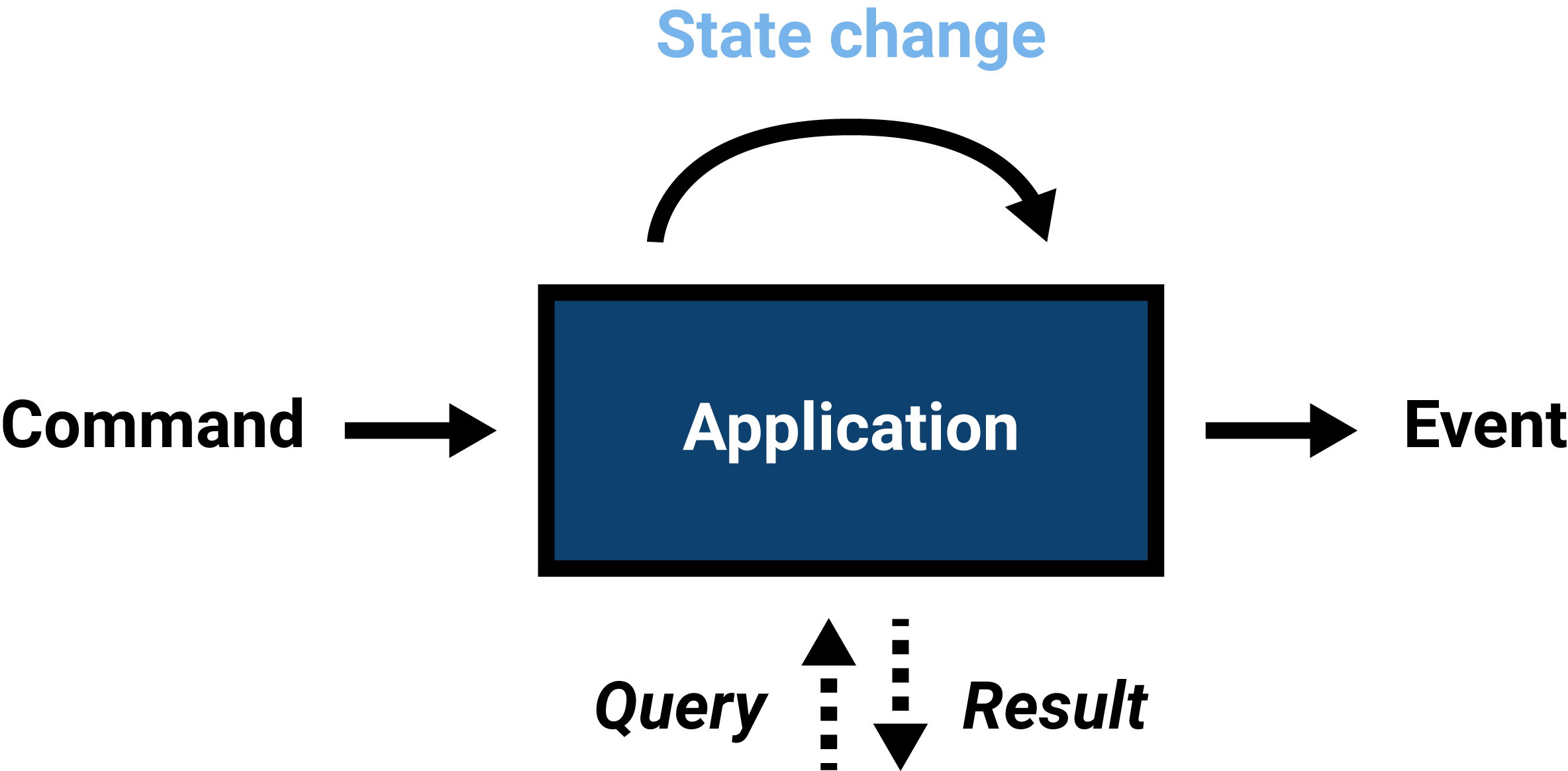
Events
An event represents something that has happened. Because events happened in the past, they are named using the past tense.
Events are the primary communication mechanism in event-driven systems. In its most basic form, one component or service causes an event, and zero, one or more others react to it depending on their interest in said event.
Reacting to events differs from traditional programming and the decoupling of sender and receiver can make an event-driven system difficult to observe. However, acting upon events, immutable statements of fact that happened at some point in time, aligns with a common mental model of reasoning about about history, consequences and causality.
Events are often notifications of changes in state.
Nothing happens, unless services or components
interested in the events in question are
setup to react or respond.
A BatteryAlmostDepleted event could trigger
a warning light in a dashboard, an InstantMessageReceived event
could cause a notification to show up in a friend’s
notification bar and a BalanceSheetImported event could start off a
data processing pipeline – each processor in the pipeline
potentially emitting and handling consequent events.
Commands
A command represents something that is intended or requested to happen. Its name is in the imperative form, because action is desired.
Commands can signify a request for mutating state. For example,
upon seeing the warning light triggered by the BatteryAlmostDepleted
event, a user (or an automated system)
could send an EnablePowerSavingMode command which, in turn,
changes application state and could cause another
event to be emitted. Another option would be to recharge
the battery, which could result in BatteryCharging
and BatteryFullyCharged
events.
Commands can lead to events – especially if
some kind of state change has taken place.
An InstantMessageReceived event or perhaps
an InstantMessageIgnored event could be the result of
handling an SendInstantMessage command
and the BalanceSheetImported event could
be triggered after handling and processing
an ImportBalanceSheet command.
Queries
Requesting current application state or an aspect thereof is called a query. The application state is communicated back to the system that issued the request through a subsequent response.
Queries often carry a name that reflects the expectation
of getting a result. For example, imperative prefixes
such as Retrieve, List, Fetch or Get
are used. Be advised that the use of Get could
be confused with an implementation detail regarding
the underlaying transport mechanism (HTTP)
of which a query typically has no knowledge.
Command-Query Separation (CQS)
In his book Object Oriented Software Construction, Bertrand Meyer describes the principle of Command-Query Separation in relation to methods that can be invoked on objects.
It is important to emphasize that CQS was not thought of with the concept of message-driven architectures in mind. It was directed at improving object-oriented design by separating concerns at object level. In some programming languages, the concept of messages and message passing form the heart of its object model. Examples can be found in Smalltalk and Ruby. In this context, messages are similar to methods that can be invoked on receivers by a sender.
CQS strictly divides methods (or: routines) in commands (or: procedures) and queries (or: functions). Command methods perform actions and can produce side effects. Query methods only return data and should not produce side effects.
Asking a question should not change the answer.
Bertrand Meyer, Eiffel Presentation (slide 43, p. 22)
Side Effects, Purity and Referential Transparency
Side effects are consequences of a method that take place outside of the scope of that method, potentially changing program behaviour. Commonly, this refers to the modification of (global) state or affecting the outside world.
Pure functions are functions that have no side effects and always return the same results (a property known as side-effect idempotency). They are referentially transparant: the expression can be replaced with its resulting, underlying value without changing the program’s behaviour. Referentially transparent functions are deterministic.
For instance, consider the following add function.
const add = (a, b) => a + b;
It is referentially transparent, because, for instance,
add(1,2) can be replaced by 3, its underlying value.
Alternatively, the following add function
cannot be said to be referentially transparent.
It has a side effect. It mutates state outside its scope.
let total = 0;
const add = (a, b) => {
total = total + a + b;
return a + b;
}
The function can be seen as idempotent as it still produces the same result, but its impure, side-effect producing nature makes it referentially opaque.
One thing to keep in mind is that whenever a method causes an event to be emitted, it can be said to produce side effects as it can have consequences outside its own scope. Events will usually be the result of a state change after handling commands. Although technically impure, events could also be emitted as result of queries, for instance for logging or metrics.
It is plausible that isolation and explicitness regarding the production of side effects helps in building maintainable software as it conveys intent, seperates responsibilities and confines uncertainty. CQS could benefit reasoning about code and designing software.
Data Transfer Objects (DTOs) and Use Cases
Because messages merely describe behaviour and represent communication between systems, services or components, they can be implemented as Data Transfer Objects (DTOs): plain objects with public properties (or, if you insist, getters and setters) and no behaviour. These properties contain raw (scalar) data types, making them (de)serializable by dedicated (de)serializers.
DTOs are quite atypical from a modern object-oriented design perspective. One of the pillars of object-oriented programming, encapsulation, is directed at containing both state and behaviour in the objects responsible: you tell an object what to do and it takes care of it. Usually, you do not explicitly query a bunch of objects and process their results in a client-level object. Akin to message-passing, DTOs de-emphasize this centralisation and encapsulation of state and behaviour in objects or services, but emphasize the communication between them.
Because DTOs convey the ways an application behaves and can be interacted with, the commands and queries of an application typically reflect its use cases. This pattern can assist in a more collaborative, use case-based approach to software development. Use cases can be coded regardless of their implementation. This pairs nicely with behaviour-driven development: each use case DTO can be mapped to a feature specification.
For a basic todo list application, its use cases can be as follows:
-
Commands:
- AddTask
- RephraseTask
- RemoveTask
- FinishTask
-
Queries:
- ShowTask
- ShowAllTasks
- ShowUnfinishedTasks
- ShowFinishedTasks
Queries return results. These results can be modelled as DTOs as well, making them more serializable. Commands can result in state changes. The system could be designed to emit events upon these changes, for instance:
- Events:
- TaskAdded
- TaskRephrased
- TaskRemoved
- TaskFinished
- AllTasksFinished
- TaskListEmptied
Keep in mind that a command does not necessarily need to result in an event and, viceversa, an event does not necessarily need to be in response to a command. There need not be a one-to-one correspondence.
These messages, all representable as DTOs, are handled by command handlers, query handlers and event handlers. For events, the terms processor, listener or consumer are also common.
DTOs represent the way the outer world can interact with the application within. Command and query handlers are therefore responsible for general validation, the conversion of the DTO to domain objects and the orchestration of services that could, directly or indirectly, deal with underlying infrastructure (storage, serialization, messaging, APIs, …).
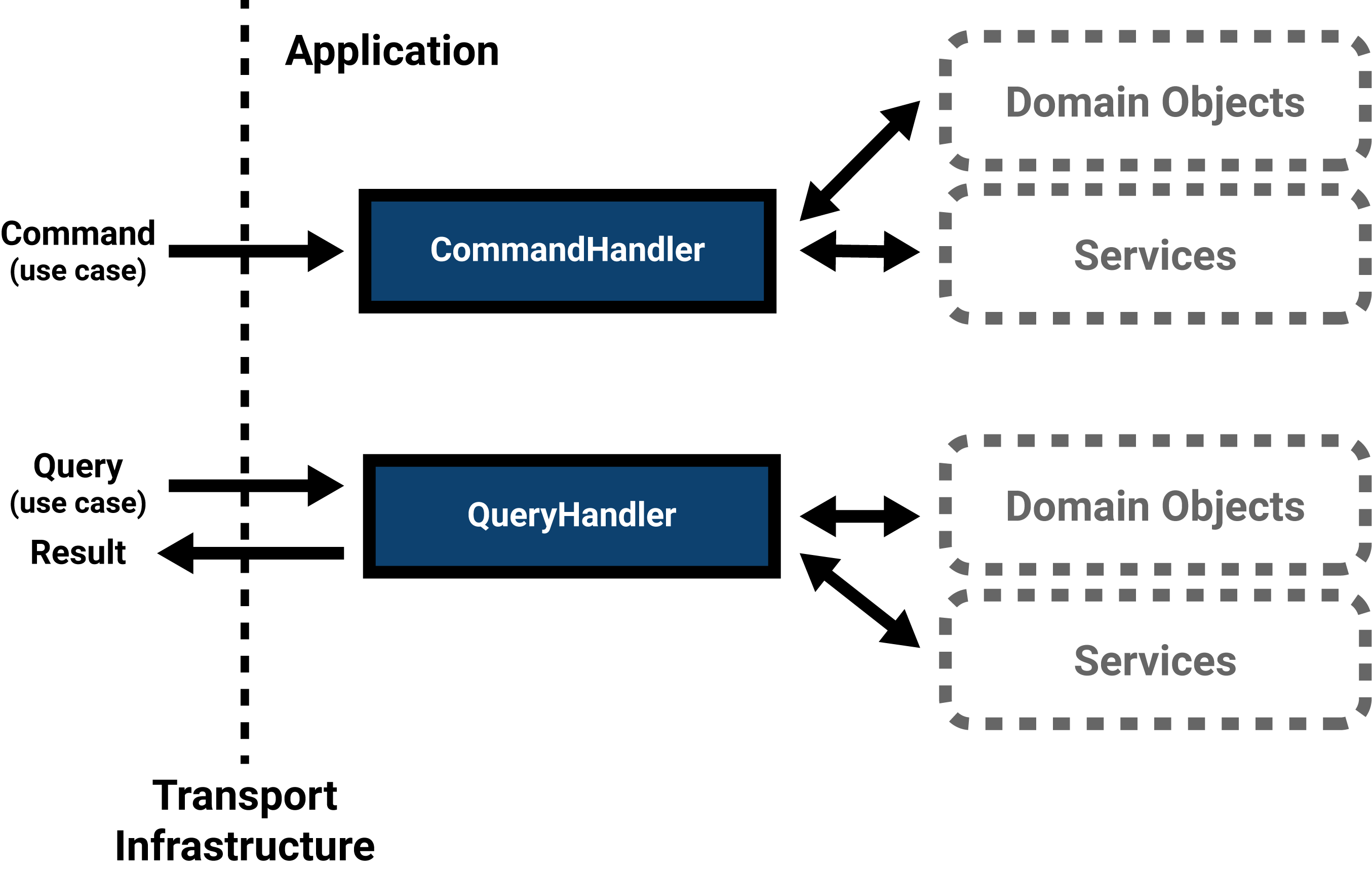
In a web application, the request comes in via HTTP; it is received by a controller or request handler. This infrastructural service builds a command or query based on the request parameters and sends it to the relevant command or query handler. This application service builds the necessary domain objects and interacts with persistance or other third-party services if necessary. If requests come in through a different means of transport, for instance through a command line interface, the DTOs are built in the adapter for that means of transport – while the rest of the application remains the same. Decoupling.
Handlers can be grouped per area of interest or, in line with the single responsibility principle, a single handler per use case can be created. Each command can be considered as one transaction.
Employing DTOs and handlers for use cases effectively separates the use cases' abstractions and their implementation details, offering a flexible design. A use case’s abstraction and implementation can be defined and evolved separately – in code and in time. This pattern pairs nicely with the ideas found in layered, decoupled architectures, such as hexagonal architecture (ports and adapters), onion architecture and clean architecture. Note that, in some architectures, use cases are not implemented through separate DTOs and handlers, but as a set of application services, orchestrating domain and infrastructural operations. It depends on the project constraints and requirements whether this amount of decoupling is possible or favorable.
In conclusion
In this post we have explored different message types: events, commands and queries. Commands, which are intended actions to happen, can result in changes in application state, which can cause events, a fact that has happened, to be emitted. Queries are requests regarding current state. These primitives can be added to a developer’s vocabulary and can be used to create a more intent-revealing design.
Command-Query Separation was originally directed at separation of concerns at object-level, but can be generalized as restricting side-effects to commands.
Messages can be modeled as DTOs: behaviourless containers of data. Commands and queries often align with the application’s use cases and are handled by command handlers an query handlers. This decouples the abstract use case from its implementation.
In later posts, we can explore how these primitives can function in an application or a service-based architecture and look at common messaging patterns and practices.
Thoughts?
Leave a comment below!